


Designing your data schema isn’t just a technical step. It’s a decision that shapes how your entire organization interacts with data, from dashboard load times to how quickly a business analyst can answer “Why are conversions down this week?”
Two of the most common database schema types for organizing analytical data are star schemas and snowflake schemas. They look similar on the surface: a central fact table with related dimension tables. But underneath, they behave very differently, and those differences can affect everything from query performance to how much storage you’re using.
In this guide, we’ll explore what these schemas are, how they differ, and which one fits best in your stack.
Table of contents:
- What is a star schema?
- What is a snowflake schema?
- 6 key differences between star schema vs snowflake schema
- When should you use a star schema?
- When is a snowflake schema better?
- Schema design in the cloud data era
- Can you use both star and snowflake schemas?
- Rethinking schema choices with ThoughtSpot
A star schema is a way of structuring your data to make it easy to understand and fast to query, especially for reporting and dashboard use cases.
At the center is the fact table, which contains measurable business data: sales, clicks, revenue, inventory changes, etc. Around it are dimension tables that add context to each fact: customers, products, dates, stores, and so on.
Each dimension table is denormalized, meaning it stores all its descriptive information in one place. A "Products" dimension, for example, might include product name, brand, category, and sub-category in a single table.
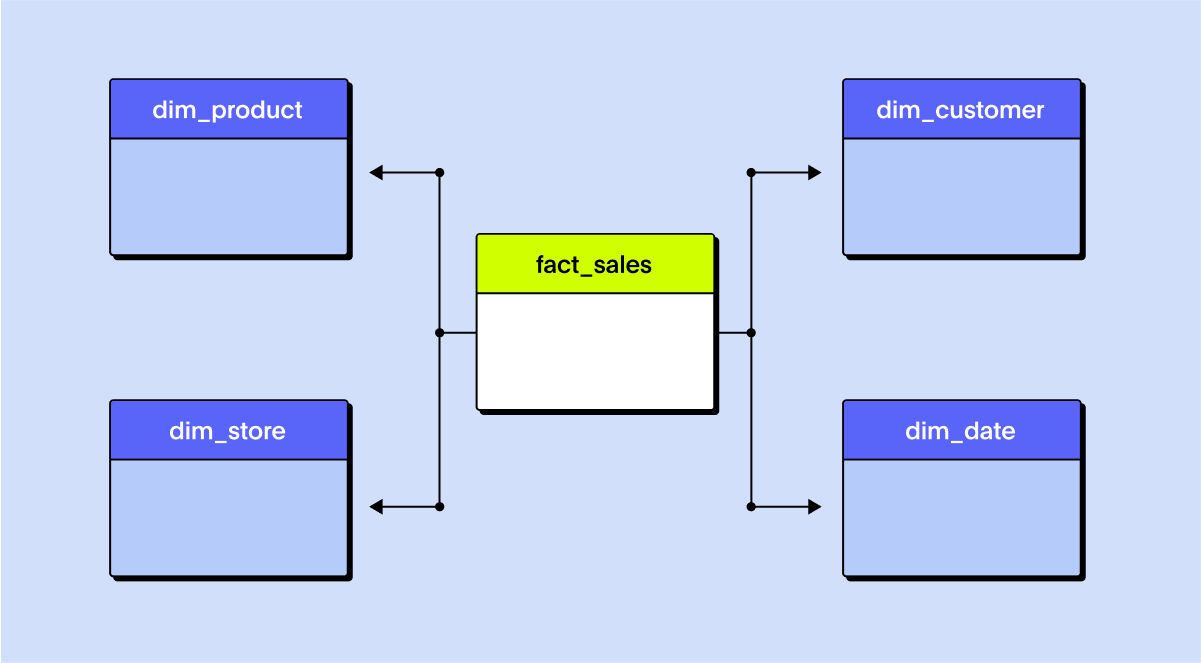
Example: Retail data in a star schema
Fact table: Sales (order_id, product_id, customer_id, date_id, sales_amount, quantity)
Dimensions:
Product (product_id, name, category, brand)
Customer (customer_id, name, location, segment)
Date (date_id, day, month, quarter, year)
Store (store_id, name, city, region)
This flat structure reduces the number of joins needed to analyze the data, which makes queries faster and easier to write.
A snowflake schema uses the same basic concept as a central fact table connected to dimension tables, but with more structure. In a snowflake schema, dimension tables are normalized, meaning they're broken down into sub-tables to remove redundancy and create hierarchical relationships.
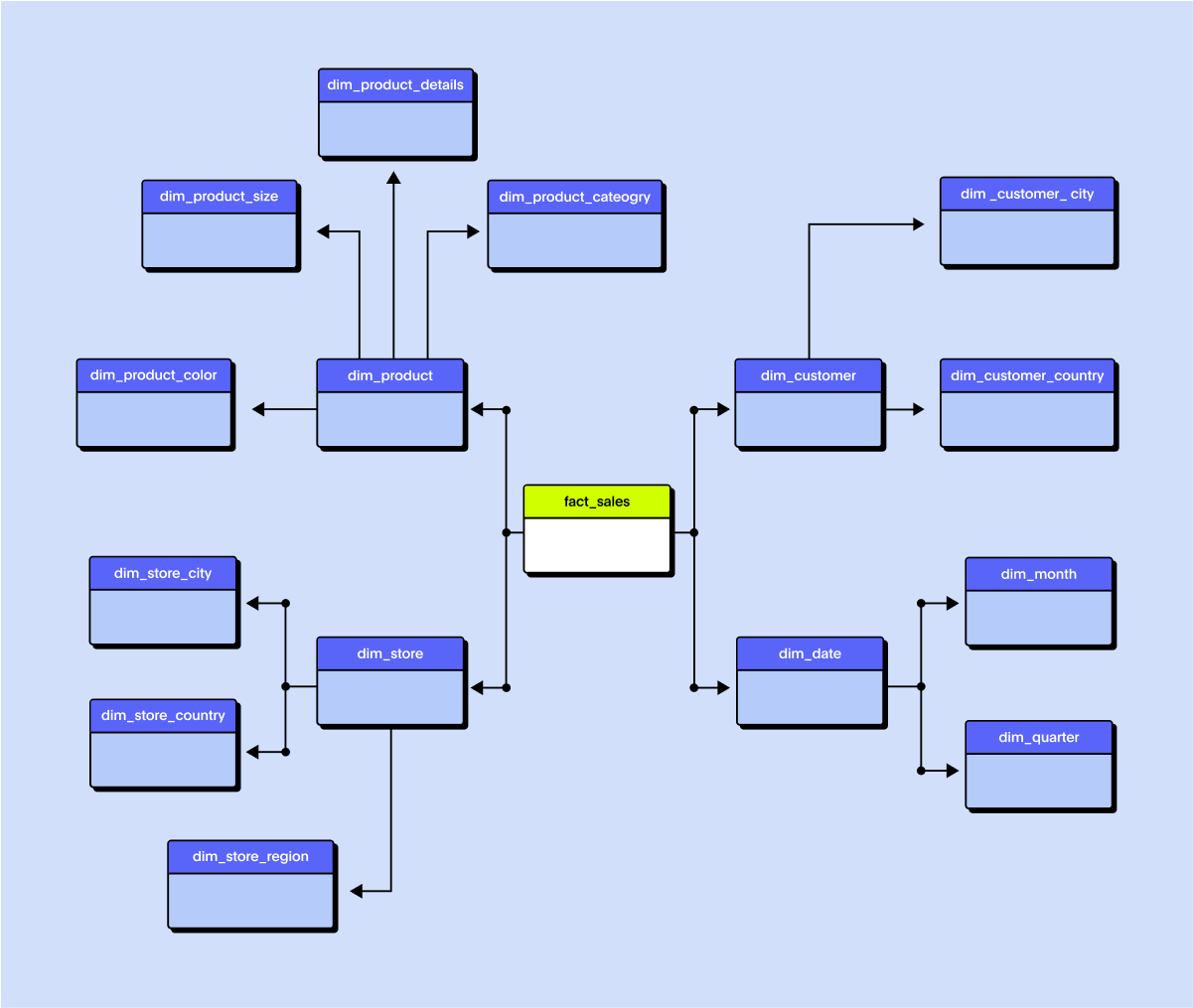
Example: Same retail data in a snowflake schema
Fact table: Sales (same as above)
Dimensions:
Product
Product → Sub-category → Category → Department
Customer
Customer → City → Region → Country
Date (often unchanged)
Store
Store → Region → Country
The result? More joins, but less duplication of data. It is especially useful for large, complex datasets where updates happen frequently.
| Aspect | Star Schema | Snowflake Schema |
|---|---|---|
| Structure | Denormalized | Normalized |
| Ease of design | Simpler, faster to set up | More complex modeling |
| Query speed | Faster (fewer joins) | Slower (more joins) |
| Storage | Higher, due to data duplication | Lower, more efficient |
| Updates | Harder to manage consistently | Easier to update accurately |
| Debugging | Can obscure data relationships | Clearer, more traceable lineage |
1. Structure
A star schema stores all related dimension data in a single, denormalized table, where product name, category, and brand all sit together.
While a snowflake schema splits that same data across normalized tables, like one for product, another for category, and a third for brand.
This makes the star schema flatter and easier to query, while the snowflake schema more accurately reflects real-world hierarchies.
2. Ease of design
A star schema is easier and faster to design because it avoids deep normalization, you create a fact table and a few dimension tables.
While a snowflake schema requires more forethought, defining hierarchies, splitting dimensions into subtables, and maintaining their relationships.
That makes star a good fit for ad hoc reporting, while snowflake works better for long-term structure and reusability.
3. Query speed
A star schema often runs faster because fewer joins are needed, a big win on large datasets.
While a snowflake schema introduces more joins across normalized tables, which can slow things down unless well-optimized.
That said, cloud data warehouses with intelligent query planning (like Snowflake or BigQuery), this performance gap is narrowing.
4. Storage
A star schema duplicates data, for example, repeating “Electronics > Smartphones > Apple” across many rows.
While a snowflake schema stores each unique value once, reducing duplication and saving space.
That can translate to lower costs in cloud environments where storage adds up.
5. Updates
A star schema can make updates painful, changing a category name might mean updating thousands of rows.
While a snowflake schema only needs one update in the related dimension table.
This makes snowflake the better choice when dimensions change frequently.
6. Debugging
A star schema can obscure data lineage since values are packed into a single table.
While a snowflake schema keeps relationships clear, making it easier to trace issues or audit data.
That clarity is crucial in industries with strict compliance or data governance needs.
A star schema is often the go-to choice when performance, simplicity, and user-friendliness are top priorities. Here’s when it shines:
You need fast, responsive dashboards. Fewer joins mean quicker queries, ideal for dashboards with real-time filters or high refresh rates.
Your data structure is relatively stable. If your data relationships don’t change often, denormalization is easier to maintain over time.
Your audience includes business users. Star schemas are easier to understand, making it simpler for analysts and stakeholders to build reports.
You're using traditional BI tools. Platforms like Tableau or Power BI perform better with flatter structures and fewer joins.
Example:
An e-commerce company wants to monitor daily sales and returns across key product categories. The data model includes a Sales Fact Table joined to flat Product, Customer, and Date dimensions. The categories don’t change often, and most reports focus on totals by day or category. A star schema offers a clean, fast, and low-maintenance solution.
A snowflake schema is more normalized and hierarchical, which brings benefits in scalability, consistency, and maintainability, especially when working with large or evolving datasets.
You want to reduce data duplication. Snowflake schemas separate repeating data into smaller tables, which lowers storage costs for large dimensions.
Your data naturally fits a hierarchy. Normalizing data into layers (e.g., category → subcategory → product) mirrors real-world relationships more accurately.
You need easier updates across shared entities. Updating a value in one normalized table reduces inconsistencies and simplifies ETL maintenance.
You’re dealing with massive datasets. Snowflake schemas keep fact tables compact and shift less-used details into dimension tables queried only when needed.
Example:
A multinational retailer tracks data across thousands of stores, dozens of countries, and deeply nested product hierarchies. The data model includes a Sales Fact Table, a Product table, and a Category table that connects to a separate Subcategory and Department table.
Here, normalization keeps everything organized and manageable, even as teams continuously add new product lines or expand into new regions.
In the world of modern cloud data warehouses, think Snowflake, BigQuery, Redshift, the old rules of schema design still apply, but they’re no longer as rigid. You still need to choose between star vs snowflake schemas, but you’re no longer boxed in by performance constraints the way you were with on-prem systems.
That’s because many of the traditional downsides of normalized schemas, like slower query performance, can now be offset by cloud-native features such as:
Materialized views: Pre-compute joins or aggregations so your normalized data can still query quickly.
Columnar storage: Fetch only the fields you need instead of entire rows, improving scan speed.
Caching: Reuse results from previous queries instead of recalculating them every time.
Query optimizers: Automatically rewrite or restructure inefficient SQL behind the scenes.
Auto-scaling compute: Add resources dynamically to handle spikes in workload or complex joins.
What does this mean in practice? You no longer have to denormalize aggressively just to keep queries fast. Star schemas are still useful, especially for simplicity and dashboard speed, but the tradeoff between performance and maintainability is more forgiving. If your data is large, complex, or inherently hierarchical, snowflaking is back on the table.
In reality, few data teams stick to a “pure” star or snowflake model. You’ll likely end up with a hybrid approach based on use case, data size, and who’s querying it.
Denormalize for speed: Dimensions that are used constantly, like time, product, or customer, are often kept flat. That means fewer joins and faster queries for the dashboards that depend on them.
Normalize for flexibility: Dimensions that are hierarchical, high-cardinality, or subject to frequent change, like employee org charts, geographies, or multi-brand structures, are better off snowflaked. They’re easier to maintain and keep clean.
Balance performance, storage, and usability: Cloud data warehouses make it easier to blend both approaches. You can materialize views, selectively flatten tables, or let your data modeling tool abstract away the complexity based on performance needs.
Example hybrid setup:
Time, Product, and Customer are flat for fast slicing in BI tools
Location is normalized into Country > Region > City > Store
Employee is normalized to support HR reports that depend on reporting lines and departmental views
This kind of hybrid schema is common in modern data stacks, where flexibility and performance both matter, and where data engineers, analysts, and business users all need different things from the same warehouse.
Modern BI tools have reshaped the way we think about data modeling, and ThoughtSpot is a prime example.
Instead of forcing you to pick sides in the star vs snowflake schema debate, ThoughtSpot lets you work with the schema that fits your data best. It doesn’t require a fully denormalized structure to perform well. Whether you’re working with a star schema, snowflake schema, or something in between, ThoughtSpot’s Agent-Powered Platform abstracts away the complexity, so you can focus on what matters: asking better questions and getting faster answers.
What sets ThoughtSpot apart:
1. Schema flexibility: No need to flatten everything into a star schema. ThoughtSpot works directly on normalized or semi-normalized structures, so your data team can model what's accurate, not just what's performant.
2. Speed meets simplicity: Whether you’re building dashboards, using live query search, or exploring data, performance stays fast thanks to smart caching, indexing, and optimized SQL generation.
3. Self-service at scale: Business teams don’t need to know what a snowflake schema is. With natural language search and guided workflows, they can explore complex data on their own, without waiting on data teams. And with Spotter, the AI Analyst, everyone gets fast, contextual answers, right where they work.
4. Built-in tools for every role: Analysts can work directly in SQL, Python, or R using Analyst Studio, while business users can track metrics and dig deeper through live, interactive dashboards.
5. Designed for the cloud stack: Built to work seamlessly with Snowflake, BigQuery, Redshift, and Databricks, so you get performance without pipeline rewrites or data reshaping.
With SnowSpot, ThoughtSpot brings agent-powered analytics to Snowflake, connecting business users, analysts, and data scientists through one unified, AI-ready experience. From natural language search and Liveboards to Spotter and Analyst Studio, you get trusted answers, intelligent agents, and powerful modeling tools, all live on your Snowflake data.
With ThoughtSpot, your schema doesn’t limit your analysis; it scales with it. See how it works–book a live demo.


