


If your business runs on data, then how you model that data matters. Not just for engineers, but for everyone making decisions based on it.
Data modeling isn’t about drawing boxes and arrows. It’s how teams get aligned, how trust is built, and how decisions scale.
In this article, we’ll break down the three layers of data modeling: conceptual, logical, and physical, and how each contributes to:
Communication between business and data teams
Clean, consistent data
Performance at scale
Future-proof architecture
Whether you’re mapping out a new data product or fixing what’s already there, understanding these layers will help you do it better and faster.
Table of contents:
- Conceptual vs logical vs physical data models: A complete comparison
- What is a conceptual data model?
- Benefits of a conceptual data model
- What is a logical data model?
- Benefits of a logical data model
- From conceptual to logical: How to evolve your model
- What is a physical data model?
- Benefits of a physical data model
- From logical to physical: The final transition
- From models to momentum
Before we dive into each model in detail, here’s a quick comparison table followed by a breakdown of how to interpret it. If you’re new to data modeling, you’ll get a sense of what each model covers, and how they build on each other.
| Aspect | Conceptual Data Model | Logical Data Model | Physical Data Model |
|---|---|---|---|
| Purpose | Define what data matters to the business | Define how the data should be structured logically | Define how the data will be implemented in a specific database |
| Audience | Business stakeholders, data architects | Data analysts, data modelers | Database admins, engineers |
| Focus | Business entities and relationships | Attributes, keys, normalization | Tables, columns, indexes, constraints |
| Technology-specific | No | No | Yes |
| Includes data types | No | Sometimes (generalized) | Yes (specific to platform) |
| Includes constraints | No | Yes (logical constraints like PKs, FKs) | Yes (PKs, FKs, not nulls, unique, etc.) |
| Normalization | Not applicable | Yes | Sometimes (may denormalize for performance) |
| Use cases | Align stakeholders on data needs | Guide database design, support analytics planning | Drive actual implementation, performance tuning, and scaling |
| Example output | High-level ER diagram | Detailed ER diagram with fields and relationships | SQL DDL scripts, database schema |
Here’s how to interpret the differences
While the conceptual model maps out high-level business entities and relationships, the logical model adds more structure, attributes, keys, and normalization, while still staying tech-agnostic.
The physical model, meanwhile, is built for implementation. While it inherits the logical model’s structure, it adds platform-specific features like data types, indexes, and partitions to boost performance.
Each one builds on the last:
Conceptual aligns business and data teams
Logical gives architects a blueprint
Physical guides backend implementation
While they serve different audiences, the three models work best together, forming a smooth progression from business understanding to technical execution.
Now that we’ve covered the big picture, let’s break down each type of data model in more detail.
We’ll explore what each one covers, who uses it, and how it fits into your overall data strategy.
A conceptual data model (CDM) is a high-level representation of the core entities in your business and how they relate to one another. It’s designed to help both technical and non-technical teams align on what data is important, without getting into the details of structure or storage.
While physical models deal with tables and data types, and logical models define relationships and keys, a conceptual model is about clarity. It’s the foundation for everything else.
A conceptual data model is:
Platform-agnostic: It doesn't rely on any specific database or tool
Business-oriented: It uses language that makes sense to stakeholders
Simple and visual: Typically captured in an entity-relationship diagram (ERD)
Example: Hotel reservation system
Here’s a simplified view of what a conceptual model might include in a hotel booking system:
| Entity | Definition | Relationship |
|---|---|---|
| Hotel | A physical location that offers rooms to guests. | Has many rooms and serves many customers. |
| Room | A sub-unit within a hotel that can be booked. | Belongs to one hotel, can be reserved by many guests. |
| Guest | Someone who stays at the hotel. | Can reserve multiple rooms; may also be a customer. |
| Customer | Anyone who makes a purchase from the hotel, such as at the gift shop. | May or may not be a guest. |
| Reservation | A record of a room booking, identified by a confirmation number. | Links a guest to a specific room for a stay. |
To bring this model to life, you’d typically represent these entities and their relationships in an entity-relationship diagram (ERD). Here’s what that might look like:
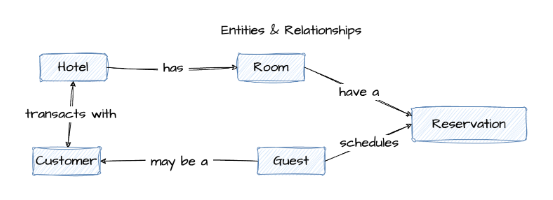
A conceptual data model might feel abstract, but it lays crucial groundwork. Here’s why it matters:
Shared understanding across teams: It bridges the gap between business stakeholders and technical teams. Everyone starts from the same definition of what matters.
Faster project alignment: With clear entities and relationships mapped early on, teams spend less time debating semantics during implementation.
Simpler communication: The model uses business-friendly terms, so you don’t need to translate tech jargon for execs or cross-functional teams.
Scalable design decisions: Because it abstracts away implementation details, the conceptual model lets you think bigger, before being constrained by tools or platforms.
Better data governance: By clarifying what entities exist and how they connect, it sets the stage for consistent naming conventions, ownership, and accountability down the line.
A logical data model (LDM) is a structured representation of data that outlines entities, attributes, and relationships without referencing any specific database or technology.
It builds on the conceptual model by introducing more detail, like primary keys and data types. Think of it as the blueprint before you start coding.
A logical data model is:
Platform-independent: Still not tied to any specific database
More detailed: Includes fields, keys, and data types (at a high level)
Normalized: Reduces redundancy for better data integrity
Example: Logical model for a hotel reservation system
Below is a sample ER diagram showing how a logical data model might look for a hotel booking use case:
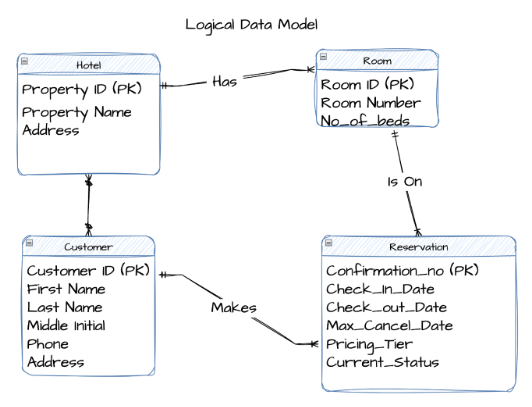
Logical models add structure without locking you into technology decisions. Here's why they’re a critical step before moving to implementation:
Stronger data integrity: With defined keys and normalized relationships, your model helps eliminate duplication and inconsistencies, so your data stays clean from day one.
Clearer structure for developers: Logical models introduce enough technical detail (like attributes and keys) to guide implementation, without diving into platform-specific syntax.
Smarter database design downstream: By working through normalization and relationships early, you reduce rework and performance issues later in the physical model.
Better alignment with business rules: You’re not just designing for storage, you’re mapping how your business actually works. That alignment helps keep systems flexible and intuitive.
Reusable foundation for multiple systems: Since it’s platform-independent, a logical model can feed into multiple databases or applications, supporting consistency across your data landscape and allowing self-service analytics that relies on well-structured, trustworthy data.
In the conceptual data model, the entities and relationships were all defined. The next step is to use data modeling best practices to turn that high-level concept into a detailed, normalized logical data model.
Here’s what that process typically involves:
Step 1: Validate your CDM
Make sure the entities and relationships in your conceptual model are correct and complete.
Step 2: Add attributes
Identify additional attributes needed for each entity.
Step 3: Identify candidate keys
Look at the attributes that uniquely identify each entity.
Step 4: Choose primary keys
Work with stakeholders to pick the best candidate as the primary key, ideally, a single field.
Step 5: Normalize the model
Use 3rd Normal Form (3NF) to eliminate redundancy. Or, if you're designing for analytics, consider dimensional modeling for performance.
Pro tip: If something doesn’t fit 3NF, try splitting it into a new entity.
Step 6: Adjust your ER diagram
As you normalize, you might need to create new entities, attributes, or relationships.
Step 7: Define relationships
Validate the relationships between entities with your stakeholders.
Pro tip: Too many relationships to a single entity? You might have a design flaw.
Step 8: Set cardinality
Decide how many instances of one entity relate to another (e.g., one-to-many, many-to-many).
Step 9: Validate the logical model
Cross-check it against business requirements to ensure it fits the real-world use case.
Step 10: Iterate and refine
Data modeling is rarely one-and-done. Update the model as requirements evolve.
A physical data model (PDM) is a technical blueprint that maps your logical data model to a specific database system, including cloud data warehouses like Snowflake or BigQuery. It outlines exactly how data will be stored, indexed, and accessed, down to the datatype, column length, and constraints.
It’s where design meets reality.
A physical data model is:
Database-specific: Tailored to a specific platform like Snowflake, BigQuery, or Postgres
Fully detailed: Includes concrete data types, indexes, constraints, and storage formats
Performance-driven: Designed to optimize query speed, storage efficiency, and scalability
Example: Physical data model for a hotel reservation system
Below is a physical data model derived from a hotel booking system. It includes concrete field types, primary and foreign keys, and relational constraints.
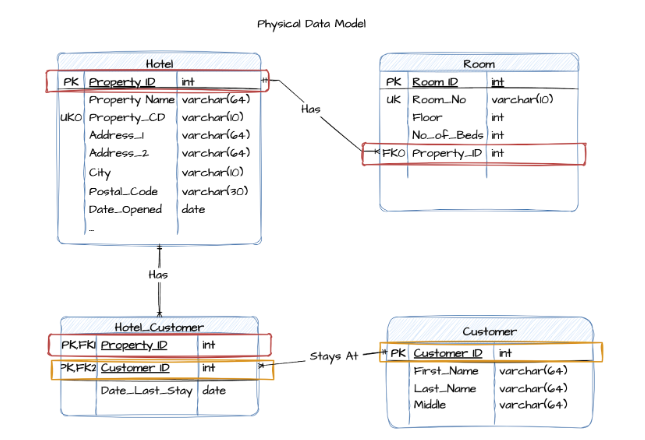
What’s different from the logical model:
Primary (PK) and foreign keys (FK) are explicitly defined
Field types like varchar(64) and int are specified based on database requirements
Indexes and constraints (e.g., UK for unique keys) are visible
Table relationships are enforced through actual referential integrity
Physical models take your design all the way to execution. Here’s why they’re essential for building performant, scalable systems:
Database-ready from day one: Unlike abstract models, a physical data model is ready to be implemented in your chosen database. It defines tables, data types, indexes, and storage rules, so your schema is production-ready.
Faster queries, better performance: With indexing, partitioning, and the right level of normalization baked in, physical models help your system handle complex queries and large volumes of data without slowing down.
Scales with your business: A well-modeled physical layer supports growth, whether that means more users, more data, or more applications. You’ve already done the work to support scaling without a major re-architecture.
Fewer data quality issues: Physical models include constraints that protect your data, like primary keys, foreign keys, and field-level rules. That means fewer bad inputs, fewer errors, and more reliable insights, all of which contribute to stronger data quality over time.
💡 Pro tip: Looking for the right data modeling tools? Make sure they support all three layers, conceptual, logical, and physical, and work well with your modern data stack.
Clear blueprint for implementation: From schema creation to storage allocation, a physical model guides DBAs and engineers through the technical build. Everyone’s aligned, and there’s less guesswork during development.
Moving from a logical data model (LDM) to a physical data model (PDM) is rarely a one-and-done task. It’s an iterative process that involves refining the structure and incorporating platform-specific details to support how the data will actually live and behave in your database.
A strong physical design starts with a solid logical model, but also demands an in-depth understanding of your cloud data platform and use case.
Here’s how that transition typically unfolds:
Step 1: Select the data platform
Decide where the data model will reside. The chosen platform will impact decisions in subsequent steps and let you take advantage of platform-specific capabilities.
Step 2: Convert logical entities into physical tables
Each entity from the logical model is mapped to one or more physical tables. Use candidate keys from the logical model to define the primary key of each table.
Step 3: Define the columns
Translate each attribute into a column and specify the appropriate data type (e.g., integer, varchar, date).
Step 4: Define relationships
Establish foreign key relationships between parent and child tables by creating a foreign key in the child table that references the parent table's primary key.
Step 5: Verify normalization (3NF)
Ensure the tables meet third normal form (3NF) to minimize redundancy and maintain data integrity. This may involve splitting or combining tables based on normalization principles and platform capabilities.
Step 6: Define indexes and partitions
Create indexes and partitions based on commonly queried fields to improve performance. Start simple (KISS: keep it simple, smarty) and optimize iteratively based on platform behavior and workload.
Step 7: Implement table constraints
Add constraints like primary keys, unique keys, null/not-null checks, and others. Even if the data platform doesn’t enforce all constraints, defining them can benefit downstream tools and applications.
Pro tip: Most cloud data platforms don’t enforce every constraint, but defining them still matters. Analytics tools and downstream apps use them to maintain data integrity and improve performance.
Step 8: Add programmability elements
Depending on your use case, implement stored procedures, views, triggers, streams, and tasks to support automation, SQL analytics, and automated data pipelines.
These elements bring your physical model to life by powering real-time operations, scheduled transformations, and custom business logic.
Step 9: Validate with stakeholders
Make sure the physical model supports the business requirements outlined in the logical model. Use test data and example queries to confirm accuracy and performance.
A well-structured logical model makes physical modeling easier, but the two aren’t a clean handoff, they’re connected, iterative stages. The goal of physical modeling is to take business intent and turn it into a working, performant, and trustworthy database design, one that reflects both how your organization thinks and how your technology behaves.
While data modeling might feel abstract, its impact is anything but. When done right, it aligns teams, reduces rework, and sets the stage for fast, confident decisions.
The conceptual model gets everyone on the same page, while the logical model adds structure, and the physical model brings it to life, each layer building on the last.
At the end of the day, your data model is your data strategy. It shapes what you track, how fast you get answers, and how well you scale.
While traditional BI tools lag behind, ThoughtSpot is built for speed. Its AI-Powered Analytics layer sits directly on your cloud data platform, so you can search, drill down, and build live dashboards on top of your physical model.
Start your free trial today and turn clean data models into real business impact.
FAQs
1. What is data modeling?
Data modeling is the process of creating a visual or conceptual representation of data and how it flows within a system. It helps define the structure, relationships, and rules that govern your data.
Think of it as the blueprint for your data, it outlines how different data elements relate to each other so teams can use and analyze information consistently.
2. What are the 5 types of conceptual models?
While “conceptual data model” usually refers to a specific type of data modeling, the term “conceptual model” is broader and spans multiple domains. In data and system design, here are five common types:
Entity-Relationship Model (ER Model): Represents data using entities (things) and relationships between them. Common in database design.
Object Role Modeling (ORM): Focuses on the roles objects play in relationships and is often used in systems analysis.
Semantic Data Model: Emphasizes meaning and context, often using ontologies and taxonomies to define relationships and constraints.
Hierarchical Model: Organizes data in a tree-like structure, where each record has a single parent and potentially many children.
Network Model: Similar to the hierarchical model but allows more complex relationships between entities (many-to-many instead of just parent-child).
3. Why do I need different types of data models? Can’t I just jump straight to the physical model?
Skipping conceptual and logical models can lead to confusion, misaligned teams, and costly redesigns. Conceptual and logical models help everyone from business stakeholders to engineers agree on what data matters and how it should be structured before diving into technical implementation.
4. What happens if my business requirements change after I build the data models?
Data modeling is an iterative process. You’ll need to revisit and adjust your models as your business evolves. That’s why starting with conceptual and logical models helps they are easier and cheaper to update before the physical model gets locked in.
5. Can a logical model be used with multiple physical databases?
Yes. Because logical models are platform-independent, you can use the same logical design as a blueprint to create multiple physical models for different database systems, which helps maintain consistency across your data environment.
6. What are some common mistakes to avoid when modeling data?
Some pitfalls include starting with physical design too early, ignoring business input, overcomplicating models with unnecessary entities or relationships, and not validating models with stakeholders regularly. Also, skipping normalization can lead to messy, redundant data.


